
Courtesy: AMD
Key Takeaways:


- End-to-end global structural pruning: Týr-the-Pruner jointly optimises pruning and layer-wise sparsity allocation, avoiding two-stage global ranking pipelines.
- Multi-sparsity supernet with expectation-aware error modelling: Layers are pruned at multiple sparsity levels and evaluated collectively to capture cross-layer dependencies.
- Coarse-to-fine evolutionary search under a fixed sparsity budget: Sparsity-shift mutations preserve global constraints while progressively refining resolution (12.5% → 1.56%).
- Taylor-informed, backprop-free local pruning: First- and second-order saliency guides structured pruning with minimal functional drift.
- Near-dense accuracy with real hardware gains: Up to 50% parameter reduction retains ~97% accuracy on Llama-3.1-70B, accelerating inference on AMD Instinct GPUs.
As large language models (LLMs) scale into the tens and hundreds of billions of parameters, pruning has re-emerged as a critical lever for improving inference efficiency without sacrificing accuracy. AMD’s Týr-the-Pruner advances this frontier with a search-based, end-to-end framework for global structural pruning, delivering up to 50% parameter reduction while retaining ~97% of dense accuracy on Llama-3.1-70B—a new state of the art among structured pruning methods.
Accepted to NeurIPS 2025, the work also demonstrates tangible inference speedups on AMD Instinct GPUs, reinforcing pruning’s relevance not just as a compression technique, but as a practical path to deployment-scale efficiency.
Why global sparsity matters
Local structural pruning is appealing for its simplicity and efficiency: layers are pruned independently, often allowing even hundred-billion-parameter models to fit on a single device. However, this approach enforces uniform per-layer sparsity, overlooking how errors and redundancies propagate across layers.
Existing “global” pruning methods attempt to address this by first ranking substructures across layers and then pruning accordingly. While intuitive, this two-stage pipeline breaks end-to-end optimisation and struggles to capture inter-layer interactions.
Týr-the-Pruner flips the paradigm. Instead of ranking structures before pruning, it first constructs a multi-sparsity supernet and then searches directly for the optimal layer-wise sparsity distribution under a fixed global budget—yielding a truly end-to-end global pruning strategy.
Inside Týr-the-Pruner: How It Works
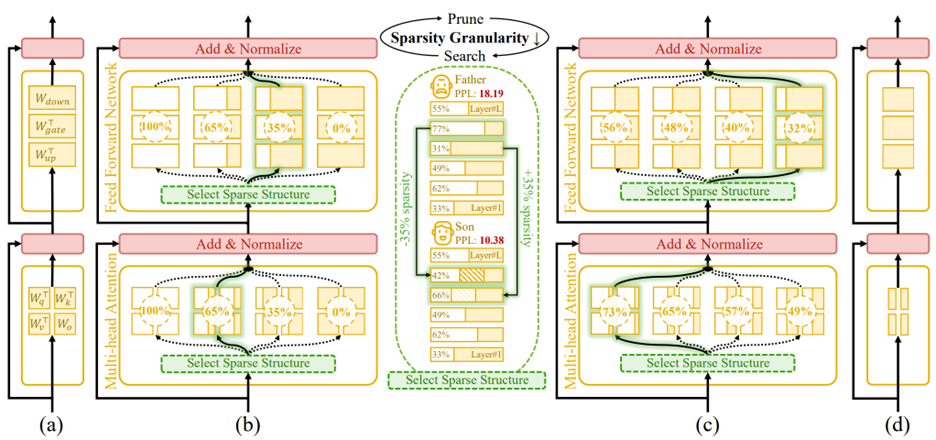
Figure 1. An overview of Týr-the-Pruner. Large language models (a) will be effectively locally pruned across multiple sparsity ratios and constructed into a supernet (b). An iterative prune-and-search strategy will be used to select the optimal sparse structure for each layer while maintaining a target overall sparsity ratio: pruning and sparsity-shift-driven evolutionary search are implemented iteratively with a coarse-to-fine sparsity interval granularity (c). Ultimately, the post-pruned LLM with the optimal sparsity distribution (d) is obtained.
Building a Reliable Supernet
The process begins by locally pruning every layer across multiple sparsity levels. Týr employs Taylor-informed saliency (first- and second-order) alongside backprop-free weight adjustment, applied progressively to minimise performance perturbations.
To ensure that different pruned variants remain mutually consistent, the framework introduces expectation-aware error accumulation, addressing the otherwise ambiguous error propagation that arises when multiple pruned copies coexist within a supernet.
Coarse-to-Fine Global Search
Once the supernet is established, Týr performs an evolutionary sparsity-shift search. Each mutation preserves the global sparsity budget—for example, making one layer slightly denser while another becomes equivalently sparser. Candidate models are evaluated using distillation-based similarity metrics over hidden activations and logits.
A naïve fine-grained search would be intractable: for an 80-sublayer model, even modest sparsity resolution would imply an astronomically large configuration space. Týr sidesteps this with an iterative coarse-to-fine strategy:
- The search begins with a coarse sparsity interval (12.5%) and just nine candidates per layer.
- After identifying a strong sparsity pattern, the search recentres and halves the interval (12.5% → 6.25% → 3.13% → 1.56%).
- After four iterations, Týr reaches fine-grained sparsity resolution while keeping each iteration’s effective search space manageable.
This design steadily narrows the search, accelerates convergence, and efficiently uncovers the optimal global sparsity distribution.
Results: Accuracy and efficiency on AMD hardware
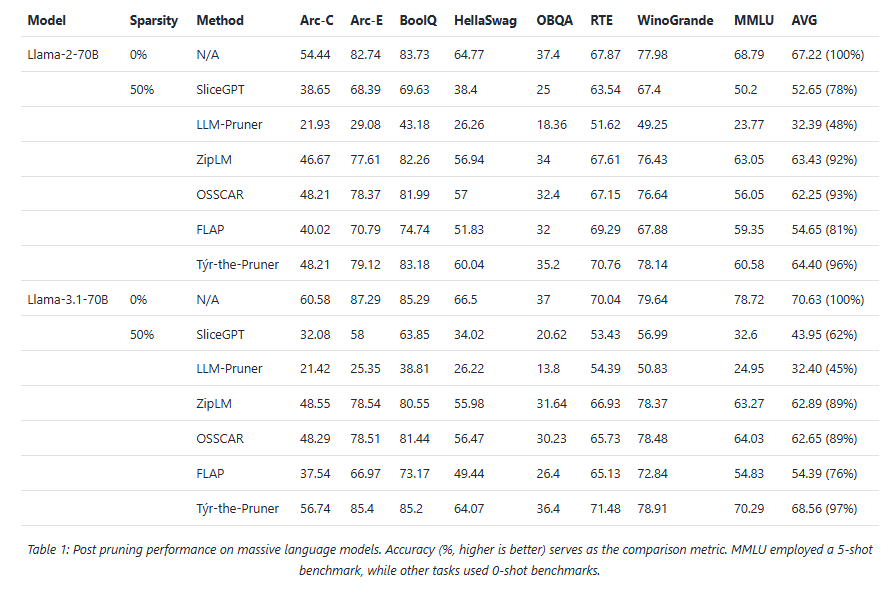
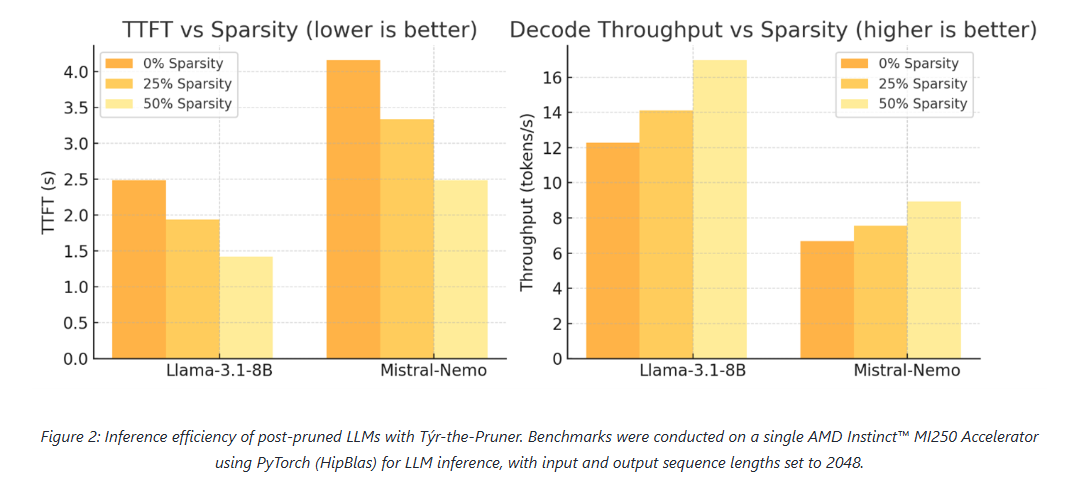
Across models and benchmarks, Týr-the-Pruner consistently preserves near-dense accuracy while delivering meaningful efficiency gains on AMD Instinct MI250 accelerators.
At 50% sparsity, the method retains 96–97% average accuracy on 70B-scale models—outperforming structured pruning approaches such as SliceGPT, LLM-Pruner, and FLAP. On smaller models, the runtime benefits are equally compelling: for Llama-3.1-8B and Mistral-Nemo, pruning cuts time-to-first-token by up to 1.75× and boosts decode throughput by up to 1.38×.
These results position pruning as a first-class optimisation technique for large-scale LLM inference, particularly on modern accelerator architectures.
Practical Considerations: Memory and Search Efficiency
While supernets can be large, Týr keeps memory usage close to that of a single dense model by storing pruned substructures on disk and loading only the active subnet into high-bandwidth memory. Disk footprints remain manageable—around 40 GB for 7–8B models and ~415 GB for 70B models—with older artefacts cleaned up between iterations.
The evolutionary search itself is computationally efficient. Evaluations proceed under progressively increasing token budgets (2K → 16K → 128K), converging rapidly thanks to the coarse-to-fine schedule. For 8B-scale models, a single search iteration completes in a few hours, keeping overall runtime well within practical limits.
Summary
Týr-the-Pruner represents a shift in how global structural pruning is approached. By unifying pruning and sparsity allocation into a single, end-to-end search process—and combining it with expectation-aware error modelling and coarse-to-fine optimisation—the framework achieves both high accuracy retention and real-world inference acceleration.
With up to 50% parameter reduction and ~97% accuracy preserved on Llama-3.1-70B, Týr-the-Pruner demonstrates that global pruning can be both principled and practical—setting a new benchmark for structured pruning in the era of large-scale LLM deployment.