
By 2030, performing inference on a large language model (LLM) with one trillion parameters will cost GenAI providers over 90% less than it did in 2025, according to Gartner, Inc., a business and technology insights company.
AI tokens are the units of data that GenAI models process. For the purposes of this analysis, a token is 3.5 bytes of data, or approximately 4 characters.




“These cost improvements will be driven by a combination of semiconductor and infrastructure efficiency improvements, model design innovations, higher chip utilisation, increased use of inference-specialised silicon, and application of edge devices for specific use cases,” said Will Sommer, Sr. Director Analyst at Gartner.
As a result of these trends, Gartner forecasts that LLMs in 2030 will be up to 100 times more cost-efficient than the earliest models of similar size developed in 2022.
The forecasted model results are split between two sets of semiconductor scenarios:
- Frontier scenarios: Model processing is based on a representation of cutting-edge chips.
- Legacy blend scenarios: Model processing is based on a representative blend of available semiconductors benchmarked to Gartner forecasts.
Modelled costs in the “blend” forecast scenarios are considerably higher than in the “frontier” scenarios, given lower computational power (see Figure 1).
Figure 1: Gartner GenAI Inference Cost Scenario Forecasts
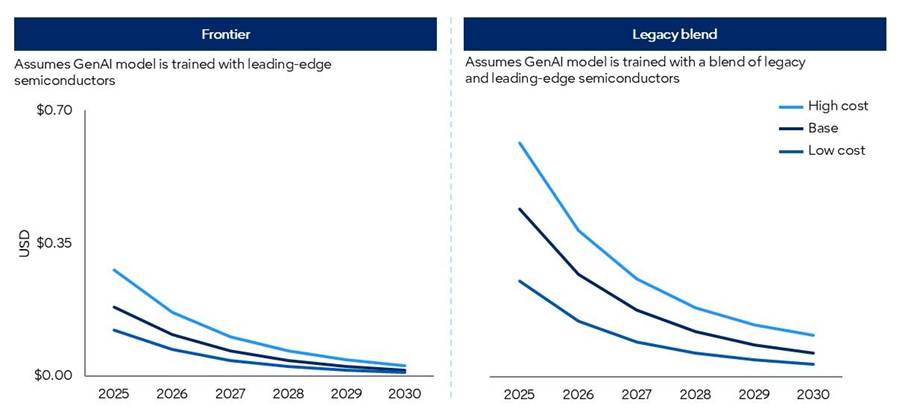
Source: Gartner (March 2026)
Falling Token Costs will not Democratize Frontier Intelligence
However, falling GenAI provider token costs will not be fully passed on to enterprise customers. Moreover, frontier intelligence will demand significantly more tokens than current mainstream applications. Agentic models, for example, require between 5-30 times more tokens per task than a standard GenAI chatbot, and can perform many more tasks than a human using GenAI.
While lower token unit costs will enable more advanced GenAI capabilities, these advancements will drive disproportionately higher token demand. As token consumption rises faster than token costs fall, overall inference costs are expected to increase.
“Chief Product Officers (CPOs) should not confuse the deflation of commodity tokens with the democratisation of frontier reasoning,” said Sommer. “As commoditised intelligence trends toward near-zero cost, the compute and systems needed to support advanced reasoning remain scarce. CPOs who mask architectural inefficiencies with cheap tokens today will find agentic scale elusive tomorrow.”
Value will accrue to platforms that can orchestrate workloads across a diverse portfolio of models. Routine, high-frequency tasks must be routed to more efficient small and domain-specific language models, which perform better than generic solutions at a fraction of the cost when aligned to specialised workflows. Expensive inference of frontier-level models must be heavily gated and reserved exclusively for high-margin, complex reasoning tasks.